Mock Data Generator
Creating mock data is a key requirement for development and testing. Typically, once developers establish their data model, they generate some mock data. However, currently users are unable to generate data through the Atlas UI which forces them to find another way to (programmatically, leveraging AI) and/or results in them getting stuck
Opportunity
Team
Product Designer, Product Manager, Engineering, User Research
Timeline
12 week exploration and design
Project Type
Experiment (vs. Control)
Design Process (a short summary)
Competitive Research
Prior to taking on the project, I reviewed previous competitive research done by another team remember. They highlighted Dbeaver, Tonic.ai, Gretel.ai, Redgate, Dataconstruct.io and Mockaroo. Mockaroo’s interface was simple and easy to understand with a straight forward goal/approach. We (product manager and I) learned that across these tools, they provided both a visual editable interface along with code samples/equivalents/editors so we made sure to prioritize those features when considering how we wanted to build our mock data creation experience.
Hackathon MVP
For MongoDB’s semi annual Hackathon, I partnered with a group of engineers to prototype out this mock data creation experience. Below are some questions we hoped to answer through this prototype.
How may we use an LLM to process a user’s data model?
How may we allow users to input data specifications?
How may we provide accurate mock data for user’s to use in testing and creating their applications?
Since the hackathon was mainly used to explore engineering feasibility with using LLMs, I provided a low fidelity mock-up with a general idea of how the user flow should be.
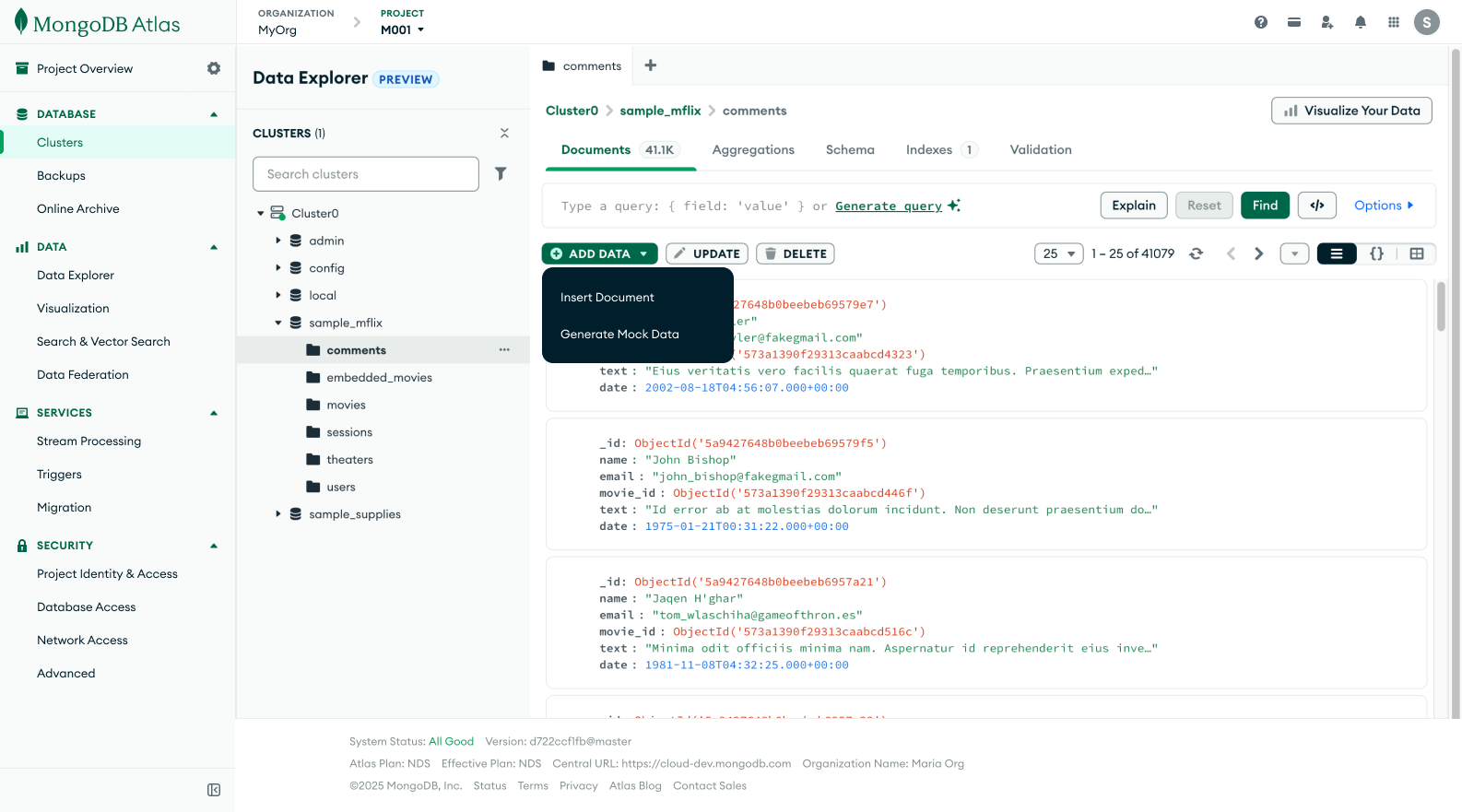
One More Modal or Try Something New
Something that our team has struggled with over the years is the amount of modal interactions we have in our product. It’s used when users want to connect their application, create an index, set up security and in many more tasks. I sometimes feel like I’m constantly designing a new modal.
Since this project is embedded within the context of a page that in itself has a lot of action oriented CTAs, I tried to explore what mock data creation could look like if I did not use a modal.
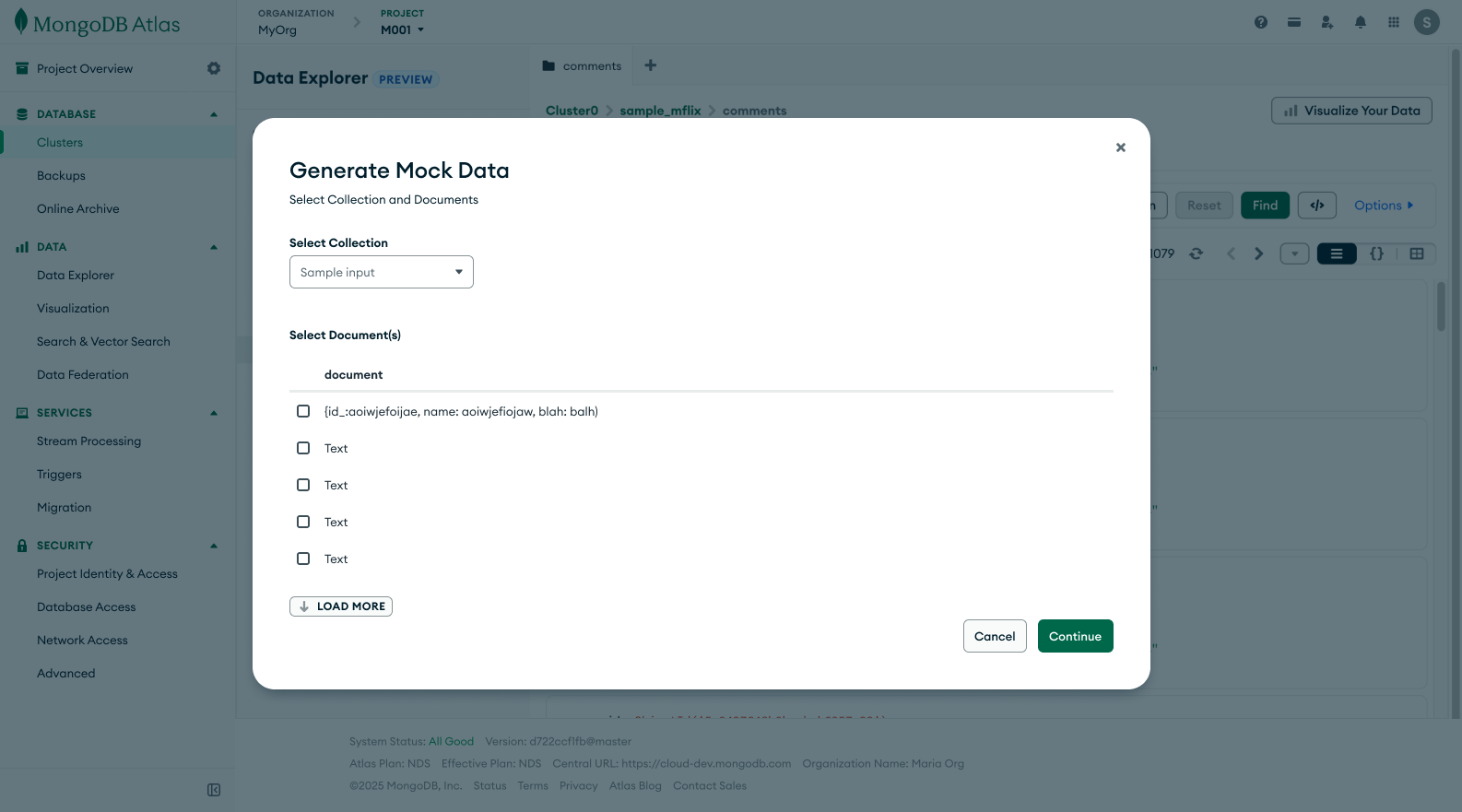
The hackathon prototype was successful but it showed us several limitations from the engineering standpoint. There were several things that the engineers had to hardcode like document selection and inputting the generated documents into the collection after they are generated. These became the engineering constraints that I kept in mind while designing.

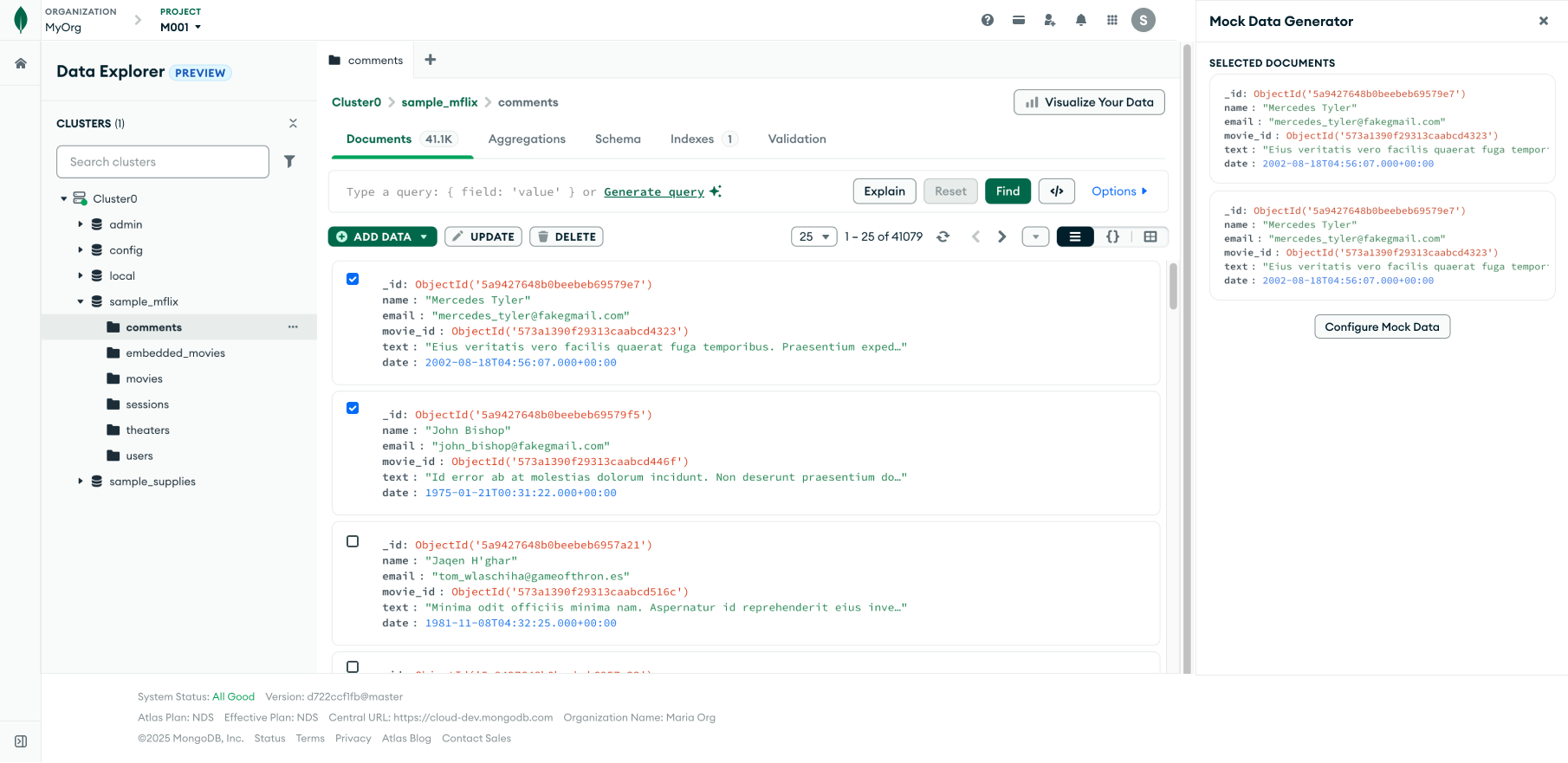
Since this project is an experiment, I do my best not to change too much of the existing design of the page but instead add on to it in a way that’s easily removable if the experiment fails. I do this by using containers like modals but in this exploration, I tried using a right side panel.
Right away I can tell that the page becomes way too busy. There’s redundant information if the right side panel shows selected documents but a disconnect in context if it doesn’t (a user could say, “why are my selections not showing up in the panel? how do I know these field names are correct and based on my selections?”). If I were to gray out the rest of the page besides the panel, then it essentially acts like a modal.
I had discussions with engineering about how to simplify the existing page. Can we disable actions that can’t be taken while the user is generating mock data? This gets into the complicated territory of changing too much of the current experience for an experiment that is not 100% likely to succeed. This creates a prioritization issue from the engineering standpoint.
Regrouping and Refocusing
After exploring the side panel, the project went on a bit of a tangent as we tried to figure out the feasibility of using something other than a modal. I got the engineers and the product manager together and we brainstormed our priorities. Since this is an experiment, if it is successful there will be more reason to convince stakeholders to allocate more resources and time into a second iteration where we can tackle some of the lesser important priorities.
To get an accurate sense of how helpful users would find this tool, it needed to:
Allow users to generate mock data based on their existing documents
Allow users to review the generated documents before inserting them into their collection
By allowing users to generate based on existing documents and insert them into the collection, we’d get a clear indicator that the user found the generated mock data related to their application needs. With these priorities aligned amongst product, design and engineering, I started on the next round of design iterations.
Designing for LLMs
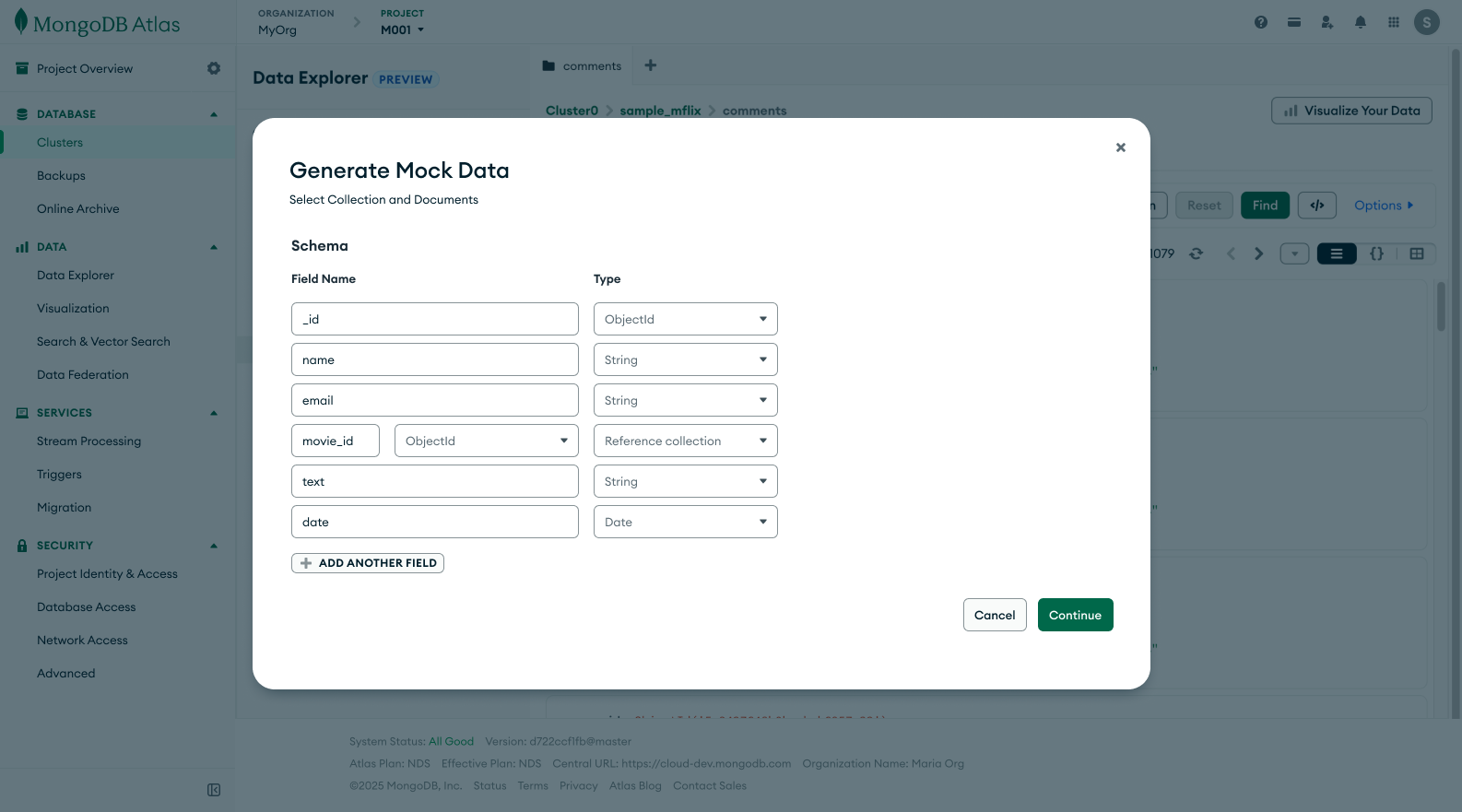
Engineering wanted to use Faker.js to generate the mock data. To do so, they had to create a mapping between the user’s field names and types to a Faker.js module. This meant from the design side, I needed to figure out how to allows users select the documents they wanted to base the mock data on and confirm the field names and types of those documents before the backend of the feature sends that information to the LLM for the mapping.
The document selection process is complicated. We didn’t have an existing way to select multiple documents. I went back to engineering to discuss the common document patterns we saw users have. I wanted to know how important it was for users to individually select documents or if one document could be representative of their general collection pattern. Engineering did some research and confirmed that one document would be sufficient as having completely different fields and types would be an anti-pattern that we warn users of. After this confirmation, we decided to randomly select a document from the collection as our sample.
The next step before sending information over to the LLM is to get confirmation about field names and type. We get this by parsing the document on the backend and showing it to the user. I felt it was important to avoid any possible errors by allowing users to edit this information if the parsing comes back inaccurate.
I advocated for user input and confirmation as sometimes AI/LLM usage can feel like a black box. Since we’re sampling straight from the user’s collection I felt it was important that they felt in control of their data. By bringing them into the user flow with confirmation steps, they’ll give us consistent feedback that they’re comfortable with the LLM usage.
Mid Fidelity Prototype
Trade-Off Considerations
Through this experiment there is a chance that we are excluding a segment of users that want to generate mock data to insert into an empty collection. Given our time constraints, we could not design and build to account for these users. Since we decided to prioritize users with existing data, we hoped that the users who found the mock data accurate and useful would be adding it into their collection. We decided to deprioritize the users with empty collections.
A experience feature that I advocated for was the ability to randomly select a different document. Since we created a way to randomly select a document, I felt it was important that if users didn’t agree with the document selected, that they could re-generate to select another document. However, this was low on the engineering priority list as they felt any random document would be suitable to base the document pattern on. Additionally, we allow users to change the field type after the LLM attempts a mapping so we felt that could catch any inconsistencies.
Outcome + Next Steps
Plan and Build
Engineering has recently started to build this out. We ran into some hiccups when it came to the legal side of LLM/AI usage but was able to align with the legal and other design teams that have been using LLM/AI in their features. After trade-offs and reprioritizing on both the design and engineering front, we have aligned on a shared vision and goal. I am excited to see how users react to this new feature and hoping it helps ease any frustrations in their development journey!